【一】SparkSQL数据源
【1】Spark SQL的DataFrame接口支持多种数据源的操作
一个DataFrame可以进行RDDs方式的操作,也可以被注册为临时表,把DataFrame注册为临时表之后,就可以对该DataFrame执行SQL查询
【2】 Spark SQL的默认数据源为Parquet格式。数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作。修改配置项spark.sql.sources.default,可修改默认数据源格式
【3】当数据源格式不是parquet格式文件时,需要手动指定数据源的格式。数据源格式需要指定全名(例如:org.apache.spark.sql.parquet),如果数据源格式为内置格式,则只需要指定简称定json, parquet, jdbc, orc, libsvm, csv, text来指定数据的格式
可以通过SparkSession提供的read.load方法用于通用加载数据,使用write和save保存数据
除此之外,可以直接运行SQL在文件上
【4】文件保存选项
①.SaveMode.ErrorIfExists(default)
“error”(default) 如果文件存在,则报错
②.SaveMode.Append
“append” 追加
③.SaveMode.Overwrite
“overwrite” 覆写
④.SaveMode.Ignore
“ignore” 数据存在,则忽略
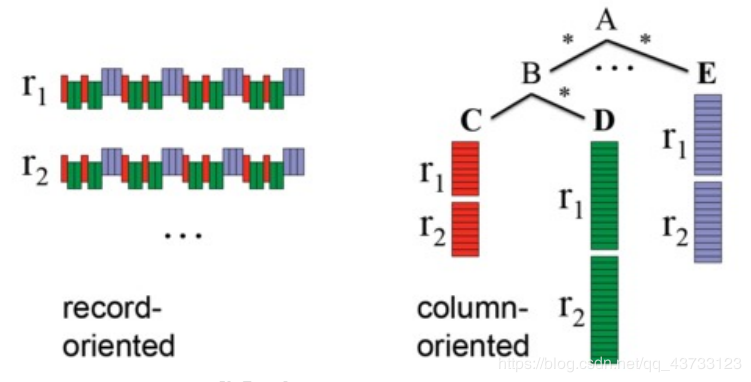
【5】Parquet文件
Parquet是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录
【6】Parquet读写
Parquet格式经常在Hadoop生态圈中被使用,它也支持Spark SQL的全部数据类型。Spark SQL 提供了直接读取和存储 Parquet 格式文件的方法
【7】Schema合并
【1】像ProtocolBuffer、Avro和Thrift那样,Parquet也支持Schema evolution(Schema演变)。用户可以先定义一个简单的Schema,然后逐渐的向Schema中增加列描述。通过这种方式,用户可以获取多个有不同Schema但相互兼容的Parquet文件。现在Parquet数据源能自动检测这种情况,并合并这些文件的Schemas
【2】因为Schema合并是一个高消耗的操作,在大多数情况下并不需要,所以Spark SQL从1.5.0开始默认关闭了该功能。可以通过下面两种方式开启该功能:
①.当数据源为Parquet文件时,将数据源选项mergeSchema设置为true
②.设置全局SQL选项spark.sql.parquet.mergeSchema为true
【5】JSON数据集
Spark SQL 能够自动推测 JSON数据集的结构,并将它加载为一个DataSet[Row]. 可以通过SparkSession.read.json()去加载一个 DataSet[String]或者一个JSON 文件.注意,这个JSON文件不是一个传统的JSON文件,每一行都得是一个JSON串
示例如下:

【6】JDBC
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中
注意,需要将相关的数据库驱动放到spark的类路径下
mysql-connector-java-5.1.38.jar
【7】运行Spark SQL CLI
Spark SQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行查询任务。需要注意的是,Spark SQL CLI不能与Thrift JDBC服务交互。
在Spark目录下执行如下命令启动Spark SQL CLI:
./bin/spark-sql
配置Hive需要替换 conf/ 下的 hive-site.xml
【9】Spark on Hive
【1】Apache Hive是Hadoop上的SQL引擎,Spark SQL编译时可以包含Hive支持,也可以不包含。包含Hive支持的Spark SQL可以支持Hive表访问、UDF(用户自定义函数)以及 Hive 查询语言(HiveQL/HQL)等。需要强调的 一点是,如果要在Spark SQL中包含Hive的库,并不需要事先安装Hive。一般来说,最好还是在编译Spark SQL时引入Hive支持,这样就可以使用这些特性了。如果你下载的是二进制版本的 Spark,它应该已经在编译时添加了 Hive 支持。
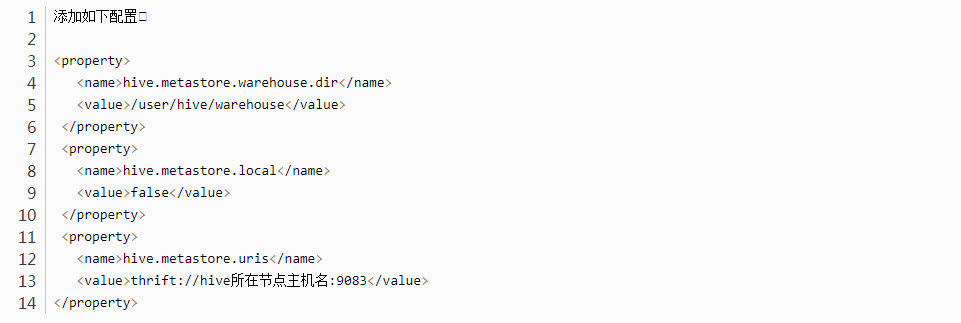
【2】Spark on Hive即为使用SparkSQL整合Hive,其实就是让SparkSQL去加载Hive 的元数据库,然后通过SparkSQL执行引擎去操作Hive表内的数据,所以首先需要开启Hive的元数据库服务,让SparkSQL能够加载元数据
配置
1)vim hive-site.xml
2)后台启动 Hive MetaStore服务
3)SparkSQL整合Hive MetaStore
Spark 有一个内置的 Hive,元数据使用 Derby 嵌入式数据库保存数据,在Spark根目录下叫做metastore_db,数据存放在Spark根目录下的spark-warehouse目录中
SparkSQL 整合 Hive 的 MetaStore 主要思路就是要通过配置能够访问它, 并且能够使用 HDFS 保存 wareHouse,所以可以直接拷贝 Hadoop 和 Hive 的配置文件到 Spark 的配置目录
注:使用IDEA本地测试直接把以上配置文件放在resources目录即可
使用IDEA操作hive时添加配置 .enableHiveSupport()//开启hive语法的支持
代码示例:
【10】SparkSQL输出到MySQL
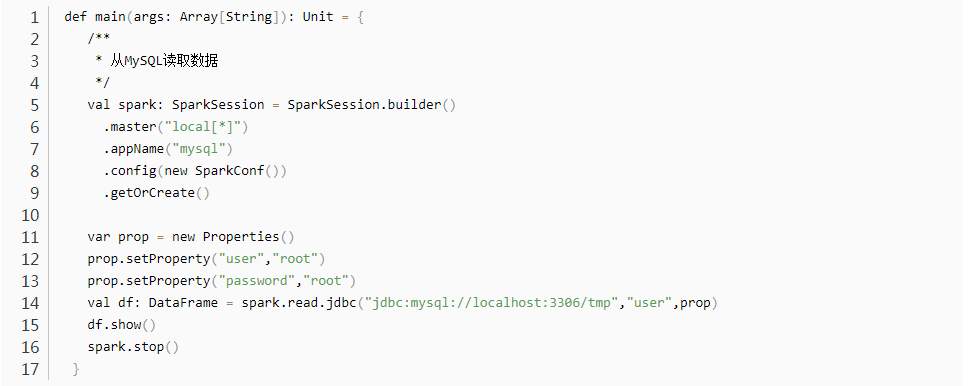
【11】SparkSQL读取MySQL数据